介绍
Atlas 是Hadoop的数据治理和元数据框架,是一组可伸缩和可扩展的核心基础治理服务。
Atlas 提供开放的元数据管理和治理功能,以构建数据资产的目录,对这些资产进行分类和治理,并为数据科学家、分析师和数据治理团队提供围绕这些数据资产的协作功能。
特性
Metadata types & instances 元数据类型和实例
预定义各种 Hadoop 元数据和非 Hadoop 的元数据类型,类型可以有各种属性,还能继承其他类型。
类型的实例即实体,是具体的元数据对象信息和血缘关系信息等。
Classification 分类
可以动态的创建分类,也可以有子类
Lineage 血缘
有直观的用户图形界面来查看数据血缘,但是没有全局的血缘界面。可以用 Reset API来构建,也可以用Kafka 接口来构建
Security & Data Masking 安全性和数据屏蔽
支持对实体实例的访问控制,以及对分类Classification 的增删改
还可以和 Apache Ranger 集成,进行权限控制。
架构
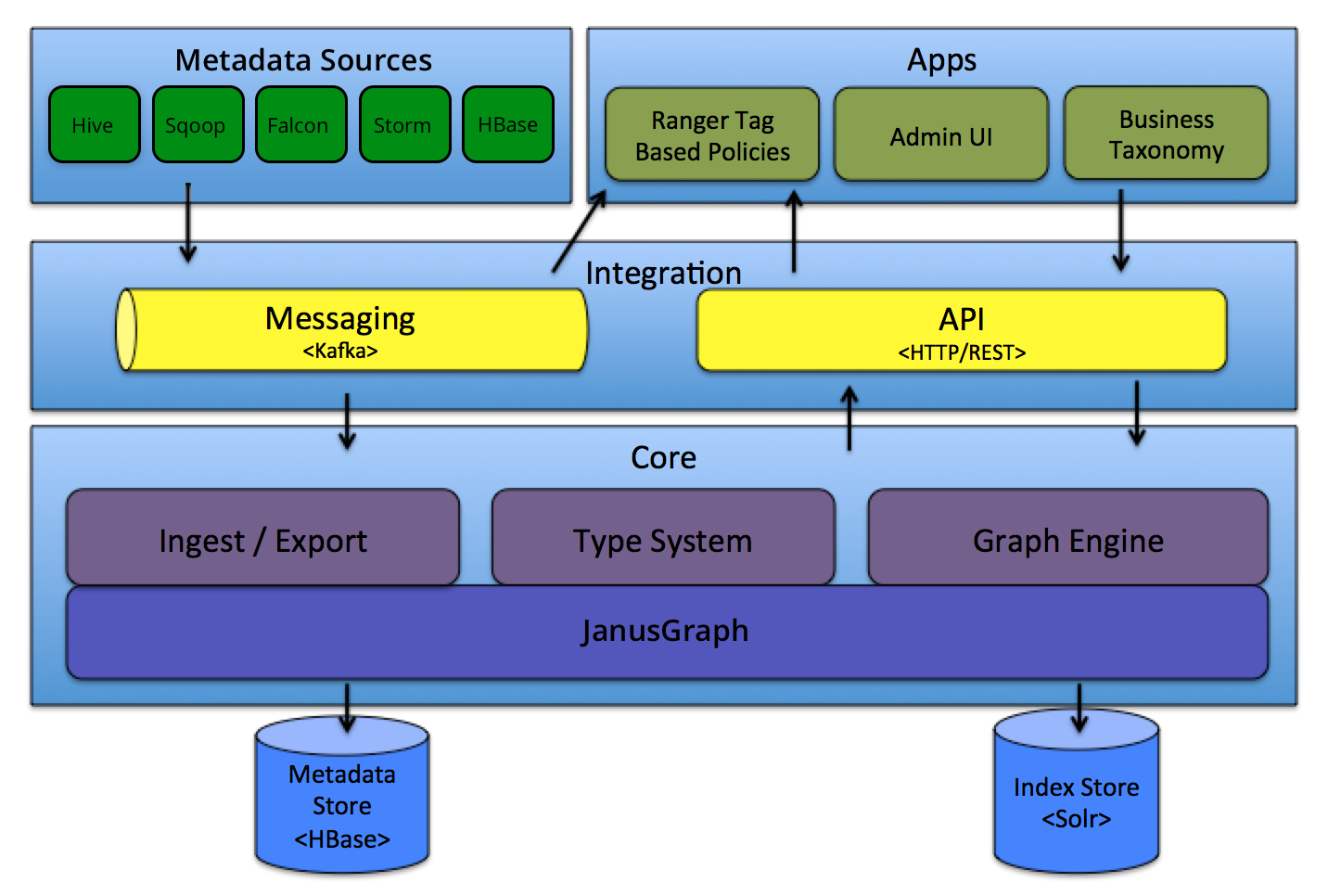
Core 核心层
- Type System:atlas 中自定义的类型系统,类似面向对象中的 类和对象。可以自定义类型 (类) 和实体 (对象),比如 hive表 default.test_table ,在 atlas 中对应的类型就是 hive_table,其实体就该表的元数据信息。
- Ingest/Export:ingest 组件用来新增元数据,export用来更新元数据。
- Graph Engine:图形引擎,负责 元数据对象之间的血缘关系,基础图形模型等。
Integration 整合层
API:Atlas 所有功能都可以通过其Rest API 来实现。
Messaging:主要是基于kafka的消息接口。此接口与 Atlas 有更好的松散耦合,更好的扩展,更好的可靠性。
ATLAS_HOOK:来自 各个组件的Hook 的元数据通知事件通过写入到名为 ATLAS_HOOK 的 Kafka topic 发送到 Atlas
ATLAS_ENTITIES:从 Atlas 到其他集成组件(如Ranger)的事件写入到名为 ATLAS_ENTITIES 的 Kafka topic
Metadata sources 元数据来源
Hive:有两个,一个是全量批量导入的,一个是基于hive hook接口实时更新元数据。包括DDL、DML
HBase:有两个,一个是全量批量导入的,一个基于 HBase 协处理器做的实时更新元数据。包括namespace、table、columnFamily等的增删改。
Sqoop:没看
Kafka:只能批量导入,即读取kafka在Zookeeper上存的相关Topic信息,进行导入。
Storm:没看
Spark:有一个 spark 的连接器,支持 spark 端的 血缘关系,但是有点复杂。
RDBMS:只有 RDBMS 的类型系统,需要自己实现 bridge 进行导入
Applications atlas应用层
- admin UI:用户界面
- Tag Based Policies:基于标签和Apache Ranger 的权限管理。