What Apache Flink
Apache Flink 是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。可部署在各种集群环境,对各种大小的数据规模进行快速计算。
分布式大数据处理引擎
- 是一个分布式的、高可用的用于大数据处理的计算引擎
有限流和无限流
- 有限流:有始有终的数据流。即传统意义上的批数据,进行批处理
- 无限流:有始无终的数据流。即现实生活中的流数据,进行流处理
有状态计算
- 良好的状态机制,进行较好的容错处理和任务恢复。同时实现 Exactly-Once 语义。
各种集群环境
- 可部署standalone、Flink on yarn、Flink on Mesos、Flink on k8s等等
Flink Application
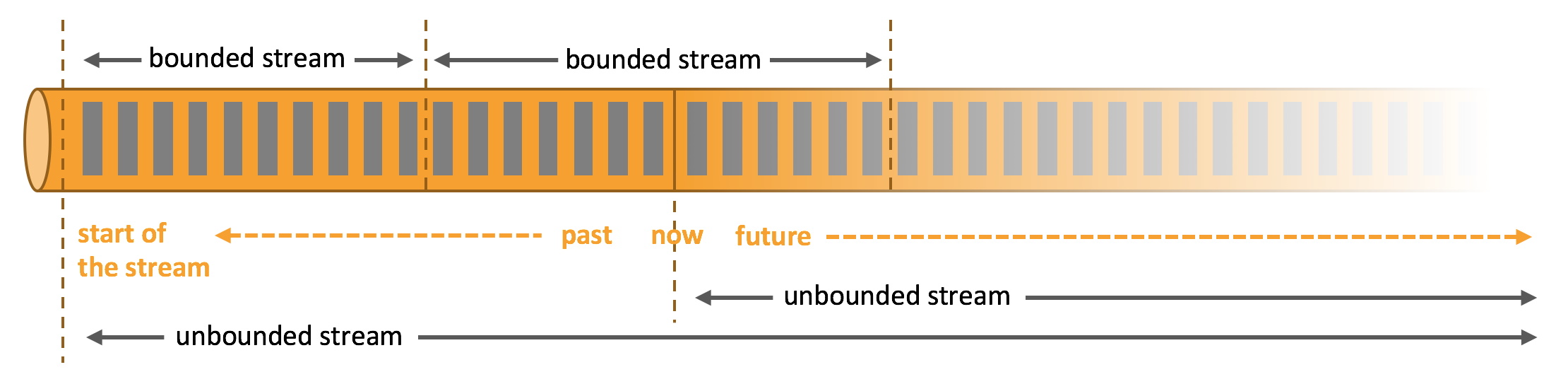
Streams
数据在真实世界中是不停产生不停发出的,所以数据处理也应该还原真实,做到真正的流处理。而批处理则是流处理的特殊情况
- 即上面说的有限流和无限流,贴官网图说明。
State
在流计算场景中,其实所有流计算本质上都是增量计算(Incremental Processing)。
例如,计算前几个小时或者一直以来的某个指标(PV、UV等),计算完一条数据之后需要保存其计算结果即状态,以便和下一条计算结果合并。
另外,保留计算状态,进行 CheckPoint 可以很好地实现流计算的容错和任务恢复,也可以实现Exactly Once处理语义
Time
三类时间:
- Event Time:事件真实产生的时间
- Processing Time:事件被 Flink 程序处理的时间
- Ingestion Time:事件进入到 Flink 程序的时间
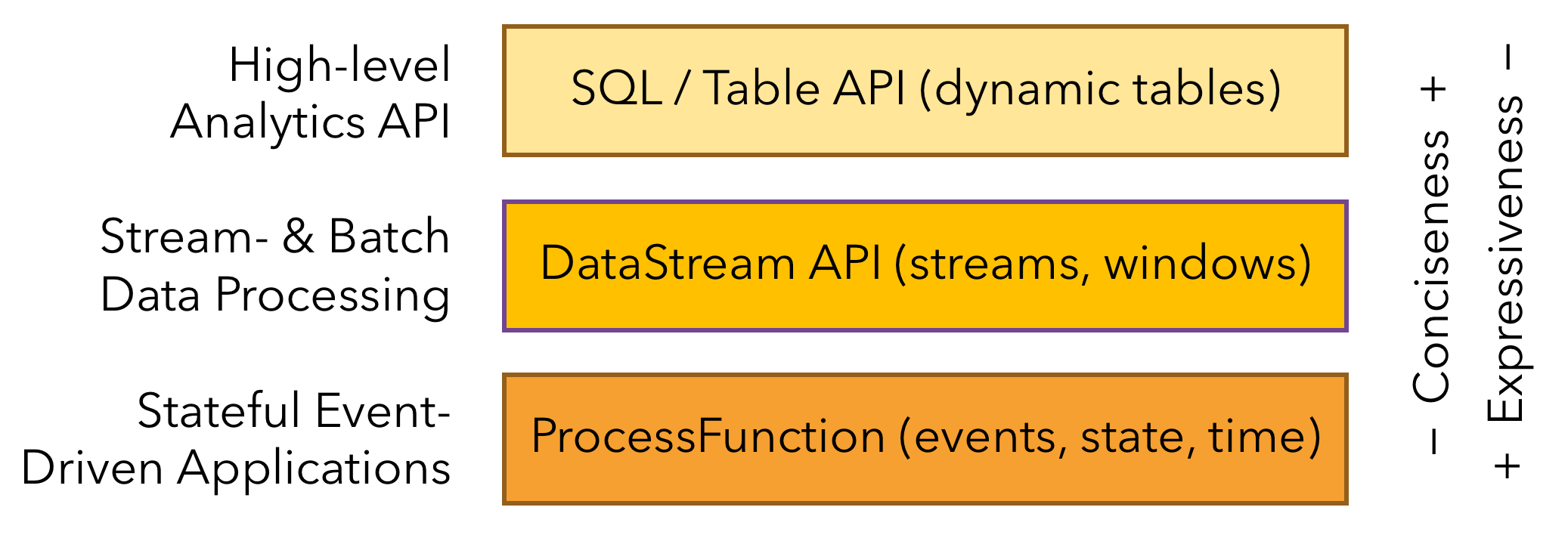
API
API分三层,越接近SQL层,越抽象,灵活性越低,但更简单易用。
- SQL/Table层:直接使用SQL进行数据处理
- DataStream/DataSet API:最核心的API,对流数据进行处理,可在其上实现自定义的WaterMark、Windows、State等操作
- ProcessFunction:也叫RunTime层,最底层的API,带状态的事件驱动。
Flink Architecture
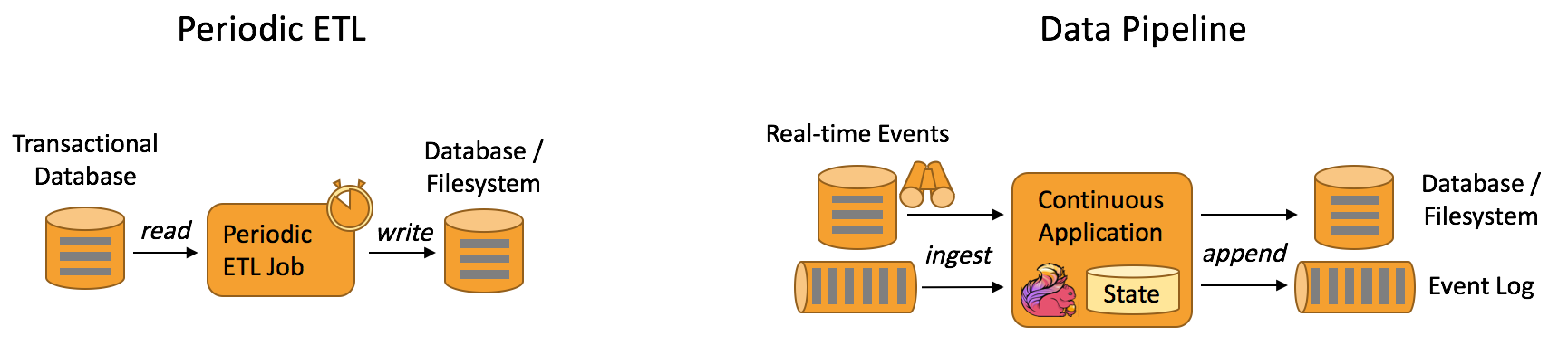
Data Pipeline Applications
即 real-time Stream ETL:流式ETL拆分。
通常,ETL都是通过定时任务调度SQL文件或者MR任务来执行的。在实时ETL场景中,将批量ETL逻辑写到流处理中,分散计算压力和提高计算结果的实时性。
多用于实时数仓、实时搜索引擎等
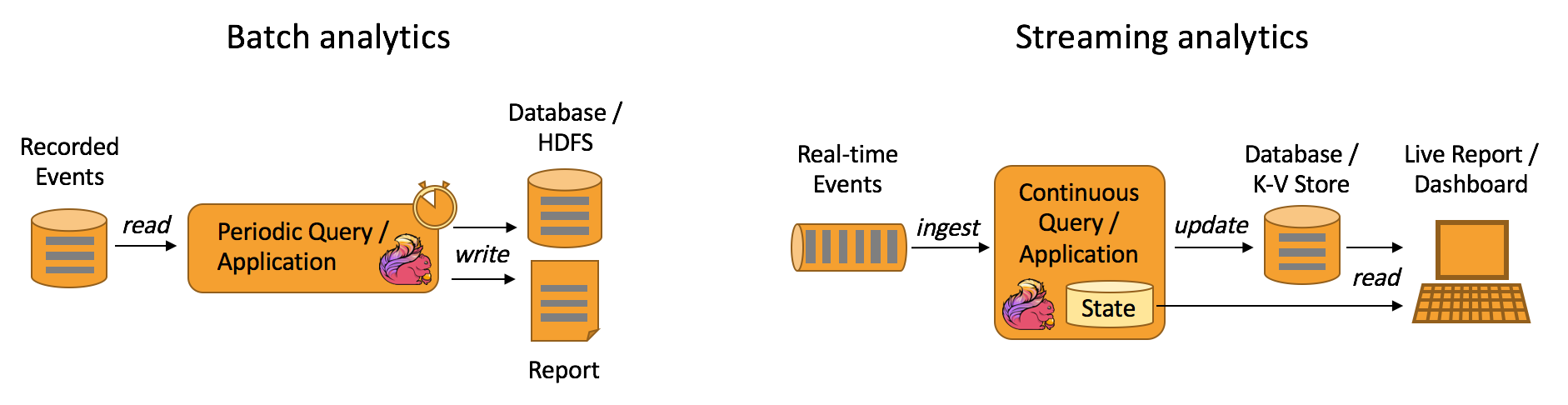
Data Analytics Applications
即数据分析,包括流式数据分析和批量数据分析。例如实时报表、实时大屏。
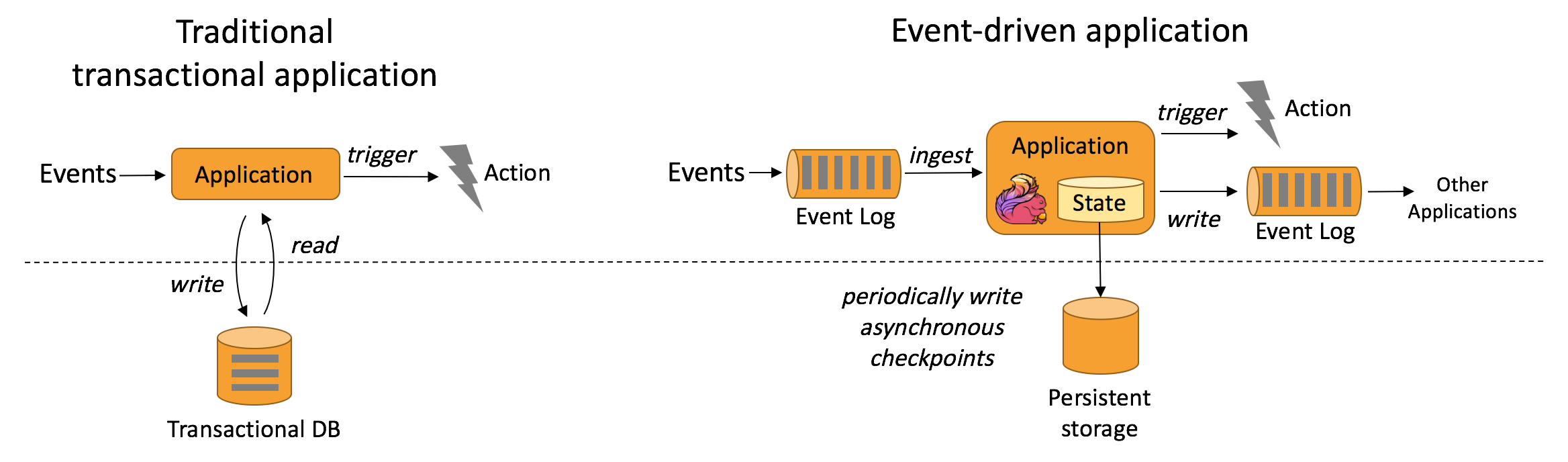
Event-driven Applications
即事件驱动应用,在一个有状态的计算过程中,通常情况下都是将状态保存在第三方系统(如Hbase Redis等)中。
而在Flink中,状态是保存在内部程序中,减少了状态存取的不必要的I/O开销,更大吞吐量和更低延时。
第一个 Flink 程序
开发环境要求
主要是Java环境和Maven环境。Java要求JDK1.8,Maven要求3.0以上,开发工具推荐使用 ItelliJ IDEA,社区说法:Eclipse在Java和Scala混合编程下有问题,故不推荐。
代码示例:
1 | package source.streamDataSource; |